+  +
+
+
+
+
+
+
+
+
+  +
+
+
+
+
+
+
+ 
 +
+
+
+


 +
+## 目录
+- [环境依赖](#环境依赖)
+- [使用预训练模型测试](#使用预训练模型测试)
+- [重新训练](#重新训练)
+- [引用](#引用)
+
+## 环境依赖
+ - [Tensorflow](https://www.tensorflow.org/) (1.12.0 <= 版本 <=1.15.0)
+ - [opencv](https://opencv.org/) == 3.4.2
+ - [pillow](https://pillow.readthedocs.io/en/latest/index.html) == 6.2.0
+ - [scipy](https://www.scipy.org/) == 1.5.2
+ - [gizeh](https://github.com/Zulko/gizeh) == 0.1.11
+
+## 使用预训练模型测试
+### 模型下载与准备
+
+在[这里](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing)下载模型:
+ - `pretrain_clean_line_drawings` (105 MB): 用于线稿矢量化
+ - `pretrain_rough_sketches` (105 MB): 用于粗糙草图简化
+ - `pretrain_faces` (105 MB): 用于自然图像到矢量草图转换
+
+然后,按照如下结构放置模型:
+```
+outputs/
+ snapshot/
+ pretrain_clean_line_drawings/
+ pretrain_rough_sketches/
+ pretrain_faces/
+```
+
+### 测试方法
+在`sample_inputs/`文件夹下选择图像,然后根据任务类型运行下面其中一个命令。生成结果会在`outputs/sampling/`目录下看到。
+
+``` python
+python3 test_vectorization.py --input muten.png
+
+python3 test_rough_sketch_simplification.py --input rocket.png
+
+python3 test_photograph_to_line.py --input 1390.png
+```
+
+**注意!!!** 我们的方法从一个随机挑选的初始位置启动绘制,所以每跑一次测试理论上都会得到一个不同的结果(有可能效果不错,但也可能效果不是很好)。因此,建议做多几次测试来挑选看上去最好的结果。也可以通过设置 `--sample`参数来定义跑一次测试代码同时输出(不同结果)的数量:
+
+``` python
+python3 test_vectorization.py --input muten.png --sample 10
+
+python3 test_rough_sketch_simplification.py --input rocket.png --sample 10
+
+python3 test_photograph_to_line.py --input 1390.png --sample 10
+```
+
+**如何复现论文展示的结果?** 可以从[这里](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing)下载论文展示的结果。这些是我们通过若干次测试得到不同输出后挑选的最好的结果。显然,若要复现这些结果,需要使用相同的初始位置启动绘制。
+
+### 其他工具
+
+#### a) 可视化
+
+我们的矢量输出均使用`npz` 文件包存储。运行以下的命令可以得到渲染后的结果以及绘制顺序。可以在`npz` 文件包相同的目录下找到这些可视化结果。
+``` python
+python3 tools/visualize_drawing.py --file path/to/the/result.npz
+```
+
+#### b) GIF制作
+
+若要看到动态的绘制过程,可以运行以下命令来得到 `gif`。结果在`npz` 文件包相同的目录下。
+``` python
+python3 tools/gif_making.py --file path/to/the/result.npz
+```
+
+
+#### c) 转化为SVG
+
+`npz` 文件包中的矢量结果均按照论文里面的公式(1)格式存储。可以运行以下命令行,来将其转化为 `svg` 文件格式。结果在`npz` 文件包相同的目录下。
+
+``` python
+python3 tools/svg_conversion.py --file path/to/the/result.npz
+```
+ - 转化过程以两种模式实现(设置`--svg_type`参数):
+ - `single` (默认模式): 每个笔划(一根单独的曲线)构成SVG文件中的一个path路径
+ - `cluster`: 每个连续曲线(多个笔划)构成SVG文件中的一个path路径
+
+**重要注意事项**
+
+在SVG文件格式中,一个path上的所有线段均只有同一个线宽(*stroke-width*)。然而在我们论文里面,定义一个连续曲线上所有的笔划可以有不同的线宽。同时,对于一个单独的笔划(贝塞尔曲线),定义其线宽从一个端点到另一个端点线性递增或者递减。
+
+因此,上述两个转化方法得到的SVG结果理论上都无法保证跟论文里面的结果在视觉上完全一致。(*假如你在论文里面使用这里转化后的SVG结果进行视觉上的对比,请提及此问题。*)
+
+
+
+
+## 目录
+- [环境依赖](#环境依赖)
+- [使用预训练模型测试](#使用预训练模型测试)
+- [重新训练](#重新训练)
+- [引用](#引用)
+
+## 环境依赖
+ - [Tensorflow](https://www.tensorflow.org/) (1.12.0 <= 版本 <=1.15.0)
+ - [opencv](https://opencv.org/) == 3.4.2
+ - [pillow](https://pillow.readthedocs.io/en/latest/index.html) == 6.2.0
+ - [scipy](https://www.scipy.org/) == 1.5.2
+ - [gizeh](https://github.com/Zulko/gizeh) == 0.1.11
+
+## 使用预训练模型测试
+### 模型下载与准备
+
+在[这里](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing)下载模型:
+ - `pretrain_clean_line_drawings` (105 MB): 用于线稿矢量化
+ - `pretrain_rough_sketches` (105 MB): 用于粗糙草图简化
+ - `pretrain_faces` (105 MB): 用于自然图像到矢量草图转换
+
+然后,按照如下结构放置模型:
+```
+outputs/
+ snapshot/
+ pretrain_clean_line_drawings/
+ pretrain_rough_sketches/
+ pretrain_faces/
+```
+
+### 测试方法
+在`sample_inputs/`文件夹下选择图像,然后根据任务类型运行下面其中一个命令。生成结果会在`outputs/sampling/`目录下看到。
+
+``` python
+python3 test_vectorization.py --input muten.png
+
+python3 test_rough_sketch_simplification.py --input rocket.png
+
+python3 test_photograph_to_line.py --input 1390.png
+```
+
+**注意!!!** 我们的方法从一个随机挑选的初始位置启动绘制,所以每跑一次测试理论上都会得到一个不同的结果(有可能效果不错,但也可能效果不是很好)。因此,建议做多几次测试来挑选看上去最好的结果。也可以通过设置 `--sample`参数来定义跑一次测试代码同时输出(不同结果)的数量:
+
+``` python
+python3 test_vectorization.py --input muten.png --sample 10
+
+python3 test_rough_sketch_simplification.py --input rocket.png --sample 10
+
+python3 test_photograph_to_line.py --input 1390.png --sample 10
+```
+
+**如何复现论文展示的结果?** 可以从[这里](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing)下载论文展示的结果。这些是我们通过若干次测试得到不同输出后挑选的最好的结果。显然,若要复现这些结果,需要使用相同的初始位置启动绘制。
+
+### 其他工具
+
+#### a) 可视化
+
+我们的矢量输出均使用`npz` 文件包存储。运行以下的命令可以得到渲染后的结果以及绘制顺序。可以在`npz` 文件包相同的目录下找到这些可视化结果。
+``` python
+python3 tools/visualize_drawing.py --file path/to/the/result.npz
+```
+
+#### b) GIF制作
+
+若要看到动态的绘制过程,可以运行以下命令来得到 `gif`。结果在`npz` 文件包相同的目录下。
+``` python
+python3 tools/gif_making.py --file path/to/the/result.npz
+```
+
+
+#### c) 转化为SVG
+
+`npz` 文件包中的矢量结果均按照论文里面的公式(1)格式存储。可以运行以下命令行,来将其转化为 `svg` 文件格式。结果在`npz` 文件包相同的目录下。
+
+``` python
+python3 tools/svg_conversion.py --file path/to/the/result.npz
+```
+ - 转化过程以两种模式实现(设置`--svg_type`参数):
+ - `single` (默认模式): 每个笔划(一根单独的曲线)构成SVG文件中的一个path路径
+ - `cluster`: 每个连续曲线(多个笔划)构成SVG文件中的一个path路径
+
+**重要注意事项**
+
+在SVG文件格式中,一个path上的所有线段均只有同一个线宽(*stroke-width*)。然而在我们论文里面,定义一个连续曲线上所有的笔划可以有不同的线宽。同时,对于一个单独的笔划(贝塞尔曲线),定义其线宽从一个端点到另一个端点线性递增或者递减。
+
+因此,上述两个转化方法得到的SVG结果理论上都无法保证跟论文里面的结果在视觉上完全一致。(*假如你在论文里面使用这里转化后的SVG结果进行视觉上的对比,请提及此问题。*)
+
+
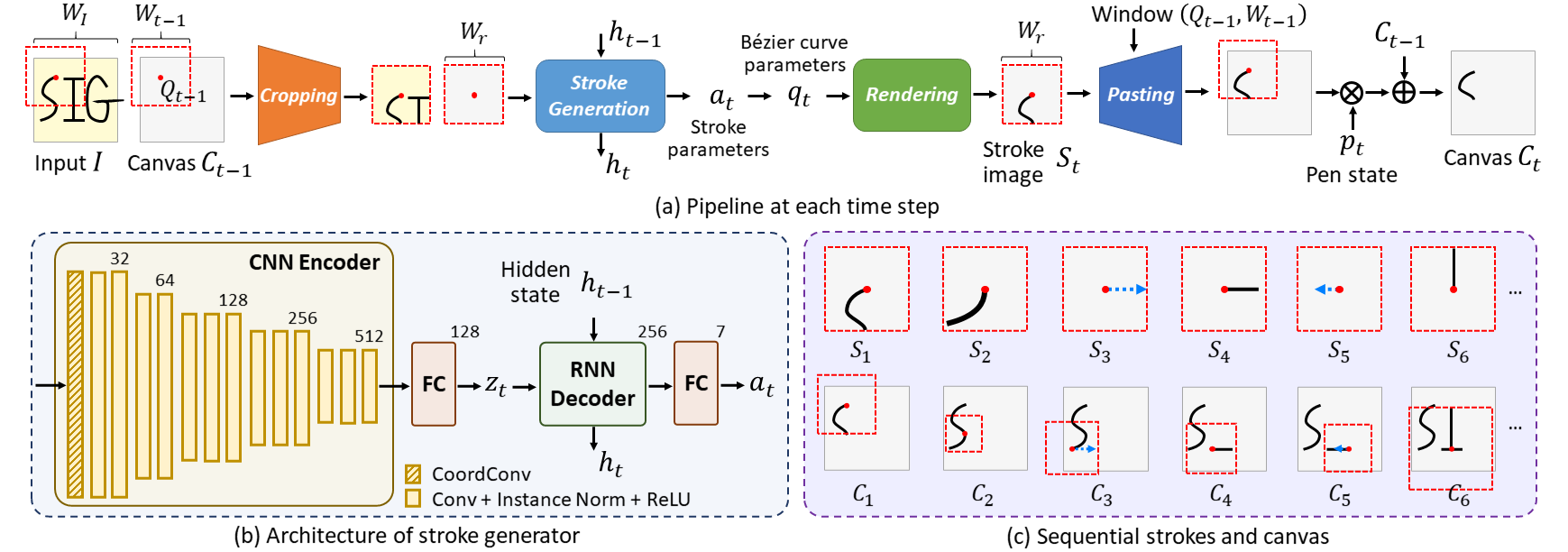
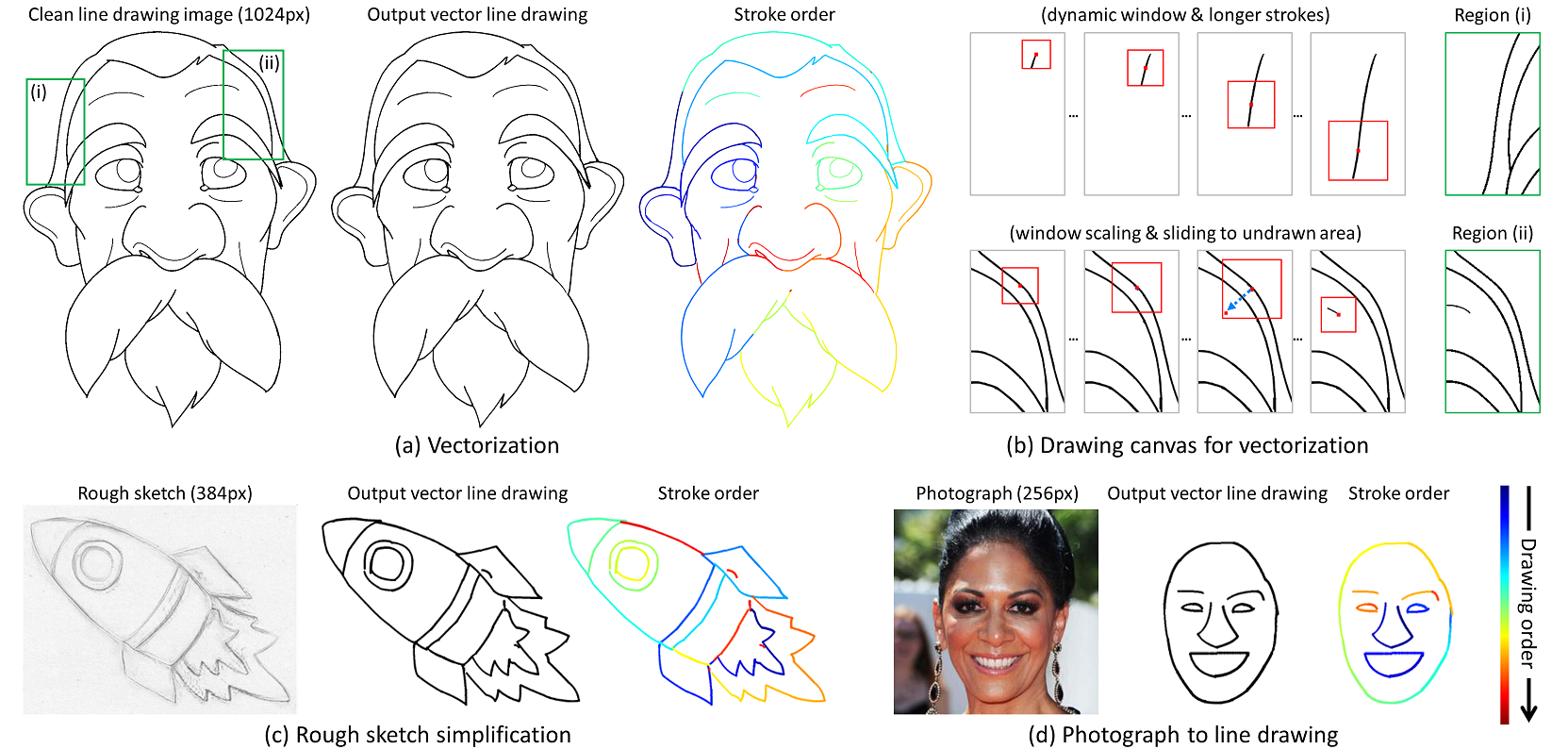
+Framework Overview
+  +
+
+
+
+ Our framework generates the parametrized strokes step by step in a recurrent manner.
+ It uses a dynamic window (dashed red boxes) around a virtual pen to draw the strokes,
+ and can both move and change the size of the window.
+ (a) Four main modules at each time step: aligned cropping, stroke generation, differentiable rendering and differentiable pasting.
+ (b) Architecture of the stroke generation module.
+ (c) Structural strokes predicted at each step;
+ movement only is illustrated by blue arrows during which no stroke is drawn on the canvas.
+
+
+
+
+
+ Overall Introduction +
+
+ (Or watch on Bilibili)
+
+ 👇
+
+ +
Vectorization
+
 |
+ + |  |
+
Rough sketch simplification
+
 |
+ 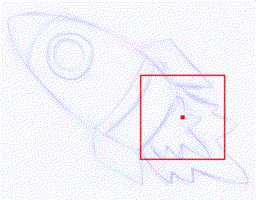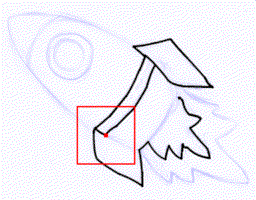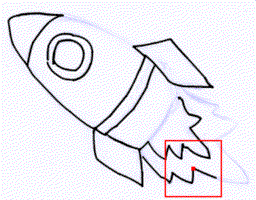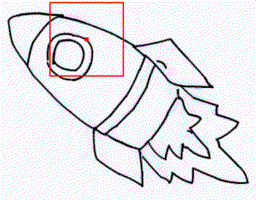 |
+ + | 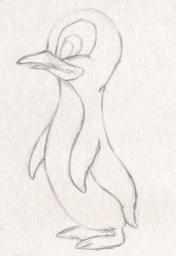 |
+ 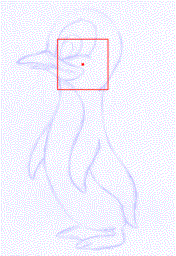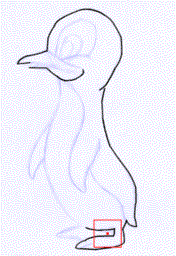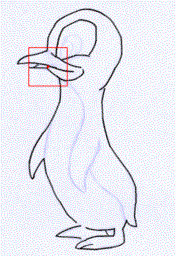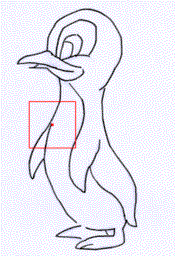 |
+
Photograph to line drawing
+
 |
+ 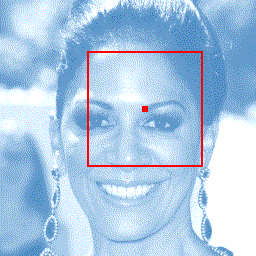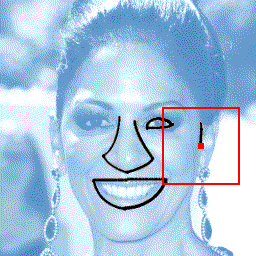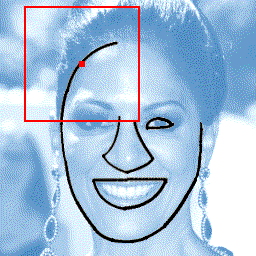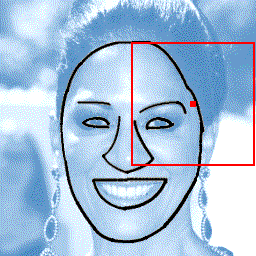 |
+ + |  |
+  |
+
+ More Results +
+
+ (Or watch on Bilibili)
+
+ 👇
+
+ +
+ 3-5 minute presentation +
+
+ (Or watch on Bilibili)
+
+ 👇
+
+ +
+@article{mo2021virtualsketching,
+ title = {General Virtual Sketching Framework for Vector Line Art},
+ author = {Mo, Haoran and Simo-Serra, Edgar and Gao, Chengying and Zou, Changqing and Wang, Ruomei},
+ journal = {ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH 2021)},
+ year = {2021},
+ volume = {40},
+ number = {4},
+ pages = {51:1--51:14}
+}
+
+
+
+
+
+
+## Outline
+- [Dependencies](#dependencies)
+- [Testing with Trained Weights](#testing-with-trained-weights)
+- [Training](#training)
+- [Citation](#citation)
+
+## Dependencies
+ - [Tensorflow](https://www.tensorflow.org/) (1.12.0 <= version <=1.15.0)
+ - [opencv](https://opencv.org/) == 3.4.2
+ - [pillow](https://pillow.readthedocs.io/en/latest/index.html) == 6.2.0
+ - [scipy](https://www.scipy.org/) == 1.5.2
+ - [gizeh](https://github.com/Zulko/gizeh) == 0.1.11
+
+## Testing with Trained Weights
+### Model Preparation
+
+Download the models [here](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing):
+ - `pretrain_clean_line_drawings` (105 MB): for vectorization
+ - `pretrain_rough_sketches` (105 MB): for rough sketch simplification
+ - `pretrain_faces` (105 MB): for photograph to line drawing
+
+Then, place them in this file structure:
+```
+outputs/
+ snapshot/
+ pretrain_clean_line_drawings/
+ pretrain_rough_sketches/
+ pretrain_faces/
+```
+
+### Usage
+Choose the image in the `sample_inputs/` directory, and run one of the following commands for each task. The results will be under `outputs/sampling/`.
+
+``` python
+python3 test_vectorization.py --input muten.png
+
+python3 test_rough_sketch_simplification.py --input rocket.png
+
+python3 test_photograph_to_line.py --input 1390.png
+```
+
+**Note!!!** Our approach starts drawing from a randomly selected initial position, so it outputs different results in every testing trial (some might be fine and some might not be good enough). It is recommended to do several trials to select the visually best result. The number of outputs can be defined by the `--sample` argument:
+
+``` python
+python3 test_vectorization.py --input muten.png --sample 10
+
+python3 test_rough_sketch_simplification.py --input rocket.png --sample 10
+
+python3 test_photograph_to_line.py --input 1390.png --sample 10
+```
+
+**Reproducing Paper Figures:** our results (download from [here](https://drive.google.com/drive/folders/1-hi2cl8joZ6oMOp4yvk_hObJGAK6ELHB?usp=sharing)) are selected by doing a certain number of trials. Apparently, it is required to use the same initial drawing positions to reproduce our results.
+
+### Additional Tools
+
+#### a) Visualization
+
+Our vector output is stored in a `npz` package. Run the following command to obtain the rendered output and the drawing order. Results will be under the same directory of the `npz` file.
+``` python
+python3 tools/visualize_drawing.py --file path/to/the/result.npz
+```
+
+#### b) GIF Making
+
+To see the dynamic drawing procedure, run the following command to obtain the `gif`. Result will be under the same directory of the `npz` file.
+``` python
+python3 tools/gif_making.py --file path/to/the/result.npz
+```
+
+
+#### c) Conversion to SVG
+
+Our vector output in a `npz` package is stored as Eq.(1) in the main paper. Run the following command to convert it to the `svg` format. Result will be under the same directory of the `npz` file.
+
+``` python
+python3 tools/svg_conversion.py --file path/to/the/result.npz
+```
+ - The conversion is implemented in two modes (by setting the `--svg_type` argument):
+ - `single` (default): each stroke (a single segment) forms a path in the SVG file
+ - `cluster`: each continuous curve (with multiple strokes) forms a path in the SVG file
+
+**Important Notes**
+
+In SVG format, all the segments on a path share the same *stroke-width*. While in our stroke design, strokes on a common curve have different widths. Inside a stroke (a single segment), the thickness also changes linearly from an endpoint to another.
+Therefore, neither of the two conversion methods above generate visually the same results as the ones in our paper.
+*(Please mention this issue in your paper if you do qualitative comparisons with our results in SVG format.)*
+
+
+ +
+  +
+
+